Artificial intelligence on premise is becoming a strategic option for companies that need control, security and performance in data processing. In this article, Mihai Iacătă, Senior Presales Consultant at Arctic Stream, briefly explains what AI is, why it is rapidly moving from experimentation to real use in the enterprise environment and which are the main benefits of running AI in one’s own infrastructure: data protection, predictable costs, easy integration with existing systems and high flexibility. The article offers a clear perspective on how on premise AI can support the digital transformation of organizations.

We live in a world where data volumes are growing exponentially and the pressure for intelligent automation and digitalization is becoming a necessity. The engine of this digital transformation has become artificial intelligence.
What is Artificial Intelligence (AI)
Artificial Intelligence, or AI, is the ability of a machine to imitate human functions such as reasoning, learning, planning and creativity. Artificial intelligence must generate real value for everyone and should not be seen as a substitute for human work, but rather as a “tool that amplifies human capabilities,” according to Microsoft CEO Satya Nadella. In the enterprise environment, the adoption of artificial intelligence has moved from the testing phase to the operational phase.
The functional modules of an AI system
A modern AI system is composed of several modules that work together to enable perception, learning, reasoning and action. In the specialized literature, these are commonly grouped into the following categories:
- Perception – the module that collects and interprets raw data from the environment: image/video processing, audio processing, feature extraction, NLP (Natural Language Processing) for text
- Knowledge representation – the AI component that understands relationships between concepts. The internal structures through which AI stores information about the world: knowledge graphs, ontologies, vectors, semantic databases
- Learning – the core element of AI that enables it to improve its performance based on data: supervised learning, unsupervised learning, reinforcement learning, model optimization
- Reasoning and inference – the decision‑making brain, the module that allows AI to draw conclusions, make predictions and take decisions through: logical systems, inference engines, probabilistic models, planning
- Planning and decision‑making – uses knowledge and reasoning to select optimal actions: short‑term/long‑term planning, optimization, action selection
- Action / Execution – the component that carries out decisions: text/content generation, robotic control, API interaction, environment manipulation
- Memory – stores experiences, states, and past results: short‑term memory, long‑term memory, experience buffer
- Interface and communication – the module that enables AI to interact with users or other systems: NLP for dialogue, APIs, communication protocols
Artificial intelligence platforms can be used in the cloud or locally, within an organization’s own infrastructure. On‑premise AI offers a unique combination of security, performance, and control that cloud‑native environments cannot fully replicate.
Choosing to implement an on‑premise AI solution brings numerous benefits:
- Data control and security: since all data processing takes place within the organization’s own infrastructure, exposure to external attacks is reduced and compliance with data residency laws becomes easier
- Performance optimization: by collocating data and compute resources, latency is minimized and model performance is optimized
- Customization: every layer of the local infrastructure can be customized, from the data network to the model container, to meet the company’s specific requirements. This level of control is difficult to achieve in a multi‑tenant cloud environment
- Cost predictability: although the initial infrastructure costs are high, local platforms can lead to a lower total cost of ownership over time by eliminating recurring usage‑based fees
- Legacy and edge integration: local systems can integrate directly with existing company software and hardware, including proprietary sensors, industrial equipment and other operational technologies. Data can be imported from existing applications without exposing the company externally
- Hardware and GPU orchestration: direct access to infrastructure management enables efficient handling of high‑performance compute resources for training and inference
- Flexible AI model lifecycle management: there is full control over deployment, versioning, rollback and seamless monitoring of models
- Advanced access controls: role‑based access control and policy‑based access can be implemented for governance and compliance
- Integrated observability: visibility is gained into AI model behavior, activity logs and infrastructure metrics
- Support for diverse models: both open‑source and closed‑source models can be hosted locally with equal ease
- Governance and auditability: all activities are traceable and compliant with internal and regulatory standards
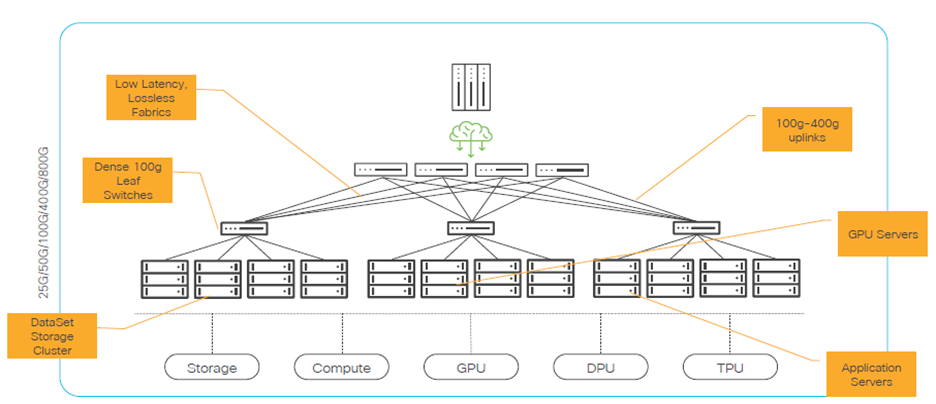
The hardware and software architecture of an on‑premise AI solution
Building an on‑premise AI solution allows complete freedom in choosing the hardware and software to be used, depending on each company’s needs. In addition to the IT component, the power and cooling systems must also be properly sized. A complex AI infrastructure differs from a traditional IT setup through its power consumption and, indirectly, through the cooling effort required. While the typical consumption for a rack equipped with standard servers, storage and networking is around 5–10 kW, in the case of a rack with GPU servers this consumption increases to about 30 kW and in some implementations with 4–6 GPU servers per rack it can reach and even exceed 60 kW, depending on the type of GPUs used.
Hardware architecture – layered approach
The network component serves as the backbone for distributed training and inference, providing high throughput and minimal latency. It consists of:
- Leaf switches (100G/200G/400G/800G) that connect directly to GPU, compute and storage nodes
- Spine/Core switches with 100–800G uplinks between the leaf and spine layers
GPU nodes (GPU servers) – the area where the actual training and inference activity takes place.
Typical configuration:
- 2–8 GPUs per node (NVIDIA B300/B200/H200/A100/L40, AMD MI300, etc.)
- 2× CPUs (x86 or ARM) with 32–64 cores each
- RAM: 512 GB – 2 TB
- 2–8× 100G NICs
- Local NVMe for scratch / cache
GPU connectivity:
- within the node: NVLink / NVSwitch
- between nodes: RoCEv2 / InfiniBand
Role in the ecosystem:
- training large models (LLM, vision, multimodal)
- large‑scale inference
- fine‑tuning, RAG, batch scoring
Compute Nodes / Application Servers – their role is to provide management and control of the platform. They offer:
- orchestration (Kubernetes/OpenShift control plane, schedulers)
- application microservices
- API gateways, front end, business logic
- feature engineering, data preparation, pre/post‑processing
As hardware, the compute nodes include fast CPUs with many cores, network interface cards with 25/50/100 GbE redundancy, and dual‑port or dual‑NIC redundancy.
DPU / SmartNIC – offloads from the CPU/GPU the network, security, and storage dataplane tasks.
Offload for:
- crypto/IPSec/TLS
- overlay networking (VXLAN/Geneve)
- storage (NVMe‑oF target/initiator)
- firewalling / microsegmentatio
It helps with multi‑tenant isolation and reduces latency jitter in AI traffic.
TPUs / specialized accelerators – these are specialized processors created by Google, optimized for tensor operations used in machine learning, especially for:
- large matrices
- multiply‑accumulate (MAC) operations (multiplying two values and adding the result to an existing sum)
- dense and convolutional neural networks
Storage Cluster – represents the primary storage source for training data, feature stores and models.
Types of storage:
- scale‑out NAS (NFS, SMB Multichannel) for large datasets
- object storage (S3‑compatible) for archives and data/model versioning
- NVMe‑oF / block storage for databases and metadata‑intensive workload
Key characteristics:
- very high sequential throughput (streaming reads for GPUs)
- high random IOPS for metadata and small files
- massive parallelism (multi‑client, multi‑stream)
- snapshot/clone capabilities for reproducible experiments
Software architecture
The first software layer of an AI infrastructure consists of the operating system and virtualization.
Node OS, Linux‑based: RHEL, Ubuntu, SLES – with:
- a kernel tuned for RDMA, huge pages, NUMA
- GPU drivers (NVIDIA, AMD), DPU drivers, InfiniBand/RoCE drivers
Virtualization / Containerization: Kubernetes / OpenShift / Rancher / vanilla k8s
The next layer is AI orchestration and scheduling, which acts as the operational brain of an on‑prem AI platform. It determines where, when and how AI jobs run (training, inference, preprocessing, MLOps pipelines) so that expensive resources: CPU, CPU, memory and networ, are used efficiently and predictably.
This orchestration role is typically handled by Kubernetes / OpenShift, Kubeflow, etc. The orchestrated actions include:
- defining GPU vs. CPU worker nodes
- launching training/inference jobs
- managing containers and services
- starting/stopping MLOps pipelines
- handling dependencies between stages
- monitoring node and GPU health
- automatically restarting failed jobs
- pod priority, resource quotas, multi‑tenancy
The role of AI scheduling determines:
- on which GPU node a job runs
- how many GPUs it receives
- how much CPU and RAM are allocated to it
- which job has priority
- how resources are shared among users
- how node overloading is avoided
The architecture continues with the AI/ML layer — frameworks and libraries. This is the layer where you find:
- machine learning frameworks (scikit‑learn, the standard for classical ML; GBoost / LightGBM / CatBoost, used in tabular scoring, fraud detection, risk scoring)
- deep learning libraries (PyTorch, the de facto standard for research and production; TensorFlow/Keras, widely used in enterprise and cloud)
- data processing tools
- hardware‑acceleration libraries (GPU, DPU, TPU)
- inference runtimes
- the Python/conda ecosystem
The data and feature engineering layer covers everything that happens between the data sources and the AI/ML frameworks. It includes:
- data collection (the data is collected, validated, normalized, transformed and loaded into a data lake or data warehouse)
- data cleaning and validation (this process includes removing missing values, correcting errors, deduplication, statistical validation, anomaly detection and format standardization)
- transformations (normalization, standardization, chunking, tokenization, vectorization)
- feature generation (feature engineering means transforming raw data into relevant features for the models)
- data versioning and governance
- preparing datasets for training and inference
It is a critical layer for performance, accuracy and reproducibility.
The MLOps and lifecycle‑management layer is the “operating system” of the entire AI platform. If the AI/ML layer is the engine, MLOps is the gearbox, the brakes, the sensors and everything that keeps the machine stable, safe and repeatable.
It is the set of processes, tools, and practices that ensure:
- development
- training
- versioning
- testing
- deployment
- monitoring
- governance
- retirement of an AI model throughout its entire lifecycle
The observability, security and governance component is what transforms an on‑prem AI platform into a robust, audited, controlled and secure enterprise solution. It is the layer that ensures everything happening within the platform is visible, controlled, compliant and protected. Observability in AI means the ability to see what is happening in the platform, in real time and historically, at the level of:
- hardware (GPU, CPU, memory, network)
- software (containers, services, pipelines)
- models (latency, drift, accuracy)
- data (streams, errors, quality)
Security in an AI platform is far more complex than in a traditional IT system, because it must protect:
- sensitive data
- models
- pipelines
- GPUs (expensive resources)
- access to inference
- access to training
Governance is the part that ensures the AI platform is:
- compliant
- audited
- controlled
- documented
- predictable
- responsible
Sizing an AI solution
Successful implementation of an on‑premise AI platform depends critically on correctly sizing the resources, because this directly influences:
- model performance
- system scalability
- operational and capital costs
- GPU utilization efficiency
- training and inference time
- user experience and platform predictability
In AI, undersizing leads to bottlenecks and idle GPUs, while oversizing leads to unnecessary costs. Balance is the key. Elements that help correctly size an AI solution:
- Number of parameters: the total number of adjustable values the model learns during training (7B, 13B, 70B, 405B)
- Context window: number of tokens processed simultaneously
- Model type: text, image, code, multimodal
- Usage mode: training, fine‑tuning, inference
- Batch size: number of examples processed at once
- Precision: FP32, FP16, bfloat16, INT8
- SLA / latency: required response time
- Concurrency: number of simultaneous users
Our team of specialists, with solid expertise in AI architectures, infrastructure, networking and security, is ready to support companies in designing and implementing high‑performance, scalable, and tailored on‑premise AI solutions. For more information or commercial inquiries, please contact us at: [email protected].