Discover how to eliminate repetitive tasks and transform data centers into efficient and scalable ecosystems. In this article, our colleague, Geanina Sandu, Data Center Engineer, invites us to explore the essential steps for moving from manual processes to automation, leveraging industry best practices and tools.

In the era of rapid digitalization, data centers have become the backbone of modern infrastructure. In the industry, there’s constant talk about scalability, operational efficiency, and continuous optimization. Buzzwords dominate the discourse: “Everything is containerized, orchestrated, and dynamically provisioned! Each node is self-healing, every flow is microsegmented and analyzed using artificial intelligence, and all services can be migrated to the cloud with a single click.” It seems like we’re living in a future where infrastructure configures itself effortlessly, everything automated end-to-end, almost instantly.

And yet, despite all these promises and high industry standards, much of the work in data centers is still done… manually. While advanced automation concepts spread across presentations and business discussions, engineers are often stuck in a much more “old-school” reality: click after click in graphical interfaces or, more often, eyes fixed on the command line, configuring network policies, adjusting firewall settings, and managing servers – all defined by… fingers. Practices ironically referred to as Finger-Defined Networking or ClickOps. Instead of automated scripts, we rely on automated clicks. Although it feels like something from the past, this manual routine persists even in the age of automation. The purpose of this article is to explore how we can avoid the ClickOps trap and build an efficient and functional automation pipeline.
The Scenario
Let’s consider a very relevant use case: onboarding a client in a data center. The onboarding process is critical to providing clients with a quick, secure, and standardized experience. At the same time, each client comes with unique requirements, including compute resources, storage, network configurations, and security policies. Automating this process can reduce implementation time and eliminate human error. We won’t delve into overly technical details, but we’ll cover the basic steps to transition from manual processes to an automated infrastructure – stress-free and with minimal time investment.
1. Defining the onboarding workflow and requirements
Planning is certainly no one’s favorite part. Everyone is eager to open their IDE and start writing the first lines of code, but before diving into automation, we need to lay the project’s foundations. Defining the workflow and requirements is essential; without this step, we risk investing time and resources in automations that provide no real value and might turn everything into a chaotic mess of useless scripts. The first question we should ask ourselves is, “Is this process even worth automating?” – and from there, we will build everything on a solid foundation.
Clarifying the requirements
To go through this first step, we need to ask ourselves some essential questions:
- What resources are available in the infrastructure? How is it currently configured, and which components could be automated?
- What types of onboarding scenarios and options are available? What are the specific steps required for each type of client? Are there any particular cases or exceptions to consider?
- What data needs to be collected to get started? How can we identify all IPs, VLANs, security policies, and essential configurations?
- How can we build a clear reference base for each stage of the automation pipeline?
- How can we efficiently test the automation process before deploying it to production?
These questions will guide us in creating an effective action plan for automating the onboarding process.
Action plan
- Infrastructure audit: review all network devices, configurations, and existing policies to gain a clear understanding of the current structure.
- Defining onboarding scenarios: develop clear onboarding scenarios for different types of clients, covering standard, customized, and complex cases, as well as possible exceptions.
- Diagrams and decision trees: visualize workflows using diagrams and decision trees to outline each step and decision point in the onboarding process, from resource allocation to configuring security policies.
- Building a source of truth: centralize information in a platform like NetBox to keep records of devices, IP addresses, clients, and other infrastructure elements up to date, serving as the single source of truth.
- Identifying automatable solutions: analyze which parts of the onboarding process can be automated.
- Setting validation points: define a testing process to ensure that every configuration is correct before implementation.
2. Configuring the automation infrastructure
After defining the workflow and requirements, the next step is to choose the right tools for automating the infrastructure. Below are some examples of commonly used solutions in network automation, each with its own advantages and use cases:
REST API
REST API allows direct configuration of network devices using HTTP requests (e.g., GET, POST, PUT, DELETE). Essentially, a REST API provides a suite of endpoints that must be accessed programmatically to interact with the infrastructure. API documentation, typically available on the vendor’s portal or within the device’s interface, describes the structure of each endpoint, including parameters and authentication requirements. Once the endpoint is identified, and the request structure is defined, the request can be sent to the device using a script in programming languages such as Python.
NETCONF and RESTCONF
NETCONF and RESTCONF are standardized protocols for configuring networks, based on YANG data models that define the structure and types of configuration data. These protocols provide access to standardized models, such as OpenConfig (for common configuration across multivendor devices) or vendor-specific models like Cisco NX-OS-device. NETCONF works over SSH and is better suited for complex and transactional configurations, supporting atomic operations and automatic rollback. RESTCONF, on the other hand, uses HTTP/HTTPS and is simpler to integrate, making it optimal for quick interactions like retrieving data or making incremental changes.
Python scripts. Python is an excellent choice for automation due to its wide range of modules that simplify network tasks. Here are some of the most useful solutions for network automation:
- Python SDKs: modules like Cisco ACI Toolkit or UCS Python SDK provide predefined functions for managing policies and interfaces, eliminating the need for direct REST API calls.
- Netmiko: a simplified library for SSH connections, compatible with multiple platforms (Cisco, Juniper, HP), enabling direct configuration via CLI.
- NAPALM: a multivendor library that abstracts common networking functions – configurations, state data collection, and compliance checks – useful in mixed equipment environments.
- Nornir: an automation framework for complex workflows, with easy integration with Netmiko and NAPALM for centralized management on a larger scale.
Ansible
Ansible is a simple and efficient automation solution based on YAML playbooks, which facilitates standardization of configurations for networks and servers. Thanks to its modularity, Ansible is compatible with a wide range of network and server platforms, making it ideal for multivendor scenarios that require a unified approach. Ansible includes dedicated modules for networks, allowing for quick and efficient configuration of key elements such as VLANs, ACLs, interfaces, and security policies on popular platforms like Cisco IOS, NX-OS, and ACI.

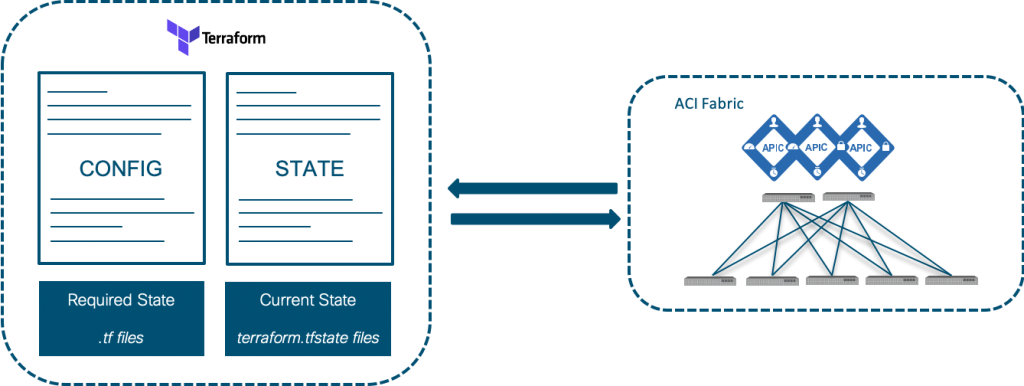
Terraform
Terraform is a powerful Infrastructure as Code (IaC) tool, ideal for managing resources both on-premises and in the cloud, in a declarative manner. Terraform allows engineers to define the desired state of the infrastructure and automatically apply the necessary changes to reach that state. A major advantage of Terraform is its support for infrastructure version control. This allows modifications to be tracked and managed in a controlled manner, enabling quick rollbacks if issues arise.
Secret management
Regardless of the chosen solution, secret management is crucial for securing automated processes. The last thing we want is to have credentials or API keys publicly exposed in a Git repo history! Tools like HashiCorp Vault allow for the secure storage of these sensitive details, reducing the risk of accidentally exposing them to scripts and configurations.

Installing automation tools
After selecting the automation tools, the next step is installing them. For centralized and efficient management, it is recommended to install all automation tools on a dedicated automation server. This can be a virtual machine on-premises or a cloud server, depending on the infrastructure and security requirements.
3. Creating and testing automation templates
After all this research, it’s time to move on to the exciting part: building automation templates and scripts. These will bring consistency, reducing errors and configuration time for each implementation.
Building templates and scripts
To create effective templates and scripts, it’s important to follow a few basic principles. First, we need to ensure they are reusable and easy to adapt, so they can be used for various configuration scenarios without major modifications. Each template will be parameterized, allowing configurations (such as VLANs, IPs, and security policies) to be customized simply by adjusting certain values.
Building a testing environment
To avoid scenarios like “who disabled all the interfaces?”, it’s critical to test templates and scripts in a controlled environment before running them in production. For this, we need to create a testing environment. To build an effective testing sandbox, a dedicated lab environment will be set up where templates and scripts can be safely executed on simulated or non-critical resources. Ideally, the testing environment should replicate production settings as closely as possible.
Running scripts and validation in the test environment
Once the testing environment is ready, it’s time to run the templates and scripts to validate their functionality. We will execute the scripts and closely monitor their behavior to ensure the outcome is as expected. If any issues arise, the templates will be adjusted before being implemented in production to avoid unpleasant surprises.
Implementation in production
Once the templates and scripts have been validated, they can be applied in production environments. It is recommended to ensure a fallback mechanism is in place before executing them in production, allowing configurations to be reset in case of unexpected bugs.
4. Integration, monitoring and maintenance
After automation is validated in production, the next step is to centralize and ensure the smooth operation of configurations by integrating them into a CI/CD pipeline, continuous monitoring, and active maintenance. These practices help maintain network stability and adapt automation to the organization’s needs.
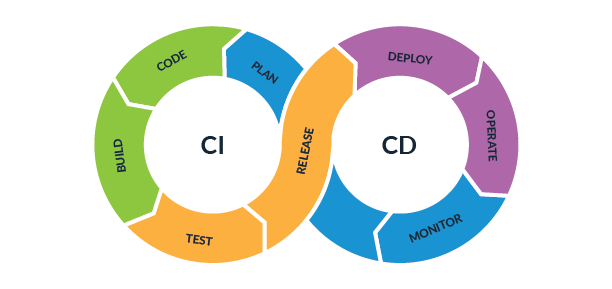
Integration into a CI/CD pipeline
Integrating automation into a CI/CD pipeline, such as Jenkins or GitLab CI/CD, ensures a centralized and efficient implementation of network changes. A CI/CD pipeline provides a step-by-step process, covering essential stages such as resource provisioning, script execution, testing, and configuration validation. Every update to templates and scripts can go through these stages of testing and approval, reducing the risk of errors and providing constant version control, which is essential for infrastructure stability.
Maintenance and continuous improvements
To keep automation relevant and functional, it is essential to have an active process for maintenance and optimization. As requirements evolve, templates and scripts will need to be updated, whether by adding new scripts or optimizing existing ones. Additionally, periodic audits help identify potential improvements and ensure that automation continues to function as expected.
Conclusions
Well-designed automation brings us closer to the ideal of a scalable, effortlessly configurable infrastructure. We’ve seen how moving from ClickOps to an efficient automation pipeline can reduce errors and simplify processes, freeing up teams from repetitive tasks and redirecting their attention to optimization and innovation. Ultimately, automation brings data centers closer to the promise of a modern infrastructure, truly prepared for the future.
If you want to transform the processes in your company’s data centers and take the step from ClickOps to DevOps, the Arctic Stream team is here to support you! Contact us at [email protected] for customized solutions and assistance in building an automation pipeline tailored to your needs.