Inteligența artificială on-premise devine o opțiune strategică pentru companiile care au nevoie de control, securitate și performanță în procesarea datelor. În acest articol, Mihai Iacătă, Senior Presales Consultant în cadrul Arctic Stream, explică pe scurt ce este AI-ul, de ce trece rapid de la experiment la utilizare reală în mediul enterprise și care sunt principalele beneficii ale rulării AI în propria infrastructură: protecția datelor, costuri predictibile, integrare ușoară cu sistemele existente și flexibilitate ridicată. Articolul oferă o perspectivă clară asupra modului în care AI on-premise poate susține transformarea digitală a organizațiilor.

Trăim într-o lume în care volumele de date cresc exponențial, iar presiunea pentru automatizare inteligență și digitalizare devine o necesitate. Motorul acestei transformări digitale a devenit inteligența artificială.
Ce este Inteligența Artificială (AI)
AI sau inteligența artificială este capacitatea unei mașini de a imita funcții umane, cum ar fi raționamentul, învățarea, planificarea și creativitatea. Inteligența artificială trebuie să genereze valoare reală pentru toată lumea și nu trebuie privită ca un substitut pentru munca umană, ci mai degrabă ca un “instrument ce amplifică capacitățile umane”, conform CEO Microsoft, Satya Nadella. În mediul enterprise adoptarea inteligenței artificiale a trecut de la faza de testare la faza de operaționalizare.
Modulele funcționale ale unui sistem AI
Un sistem AI modern este format din mai multe module care lucrează împreună pentru a permite percepția, învățarea, raționamentul și acțiunea. În literatura de specialitate, acestea sunt grupate în mod obișnuit în următoarele categorii:
- Percepția – modulul care colectează și interpretează date brute din mediu: procesare imagini / video, procesare audio, extragere de caracteristici, NLP (Natural Language Processing) pentru text
- Reprezentarea cunoștințelor – componenta AI care înțelege relațiile dintre concepte. Structurile interne prin care AI stochează informații despre lume: grafuri de cunoștințe, ontologii, vectori, baze de date semantice
- Învățare – element central al AI – permite AI să își îmbunătățească performanța pe baza datelor: învățare supravegheată, nesupravegheată, reinforcement learning, optimizare de modele
- Raționament și inferență – creierul decizional, modulul care permite AI să tragă concluzii, să facă predicții și să ia decizii prin: sisteme logice, motoare de inferență, modele probabilistice, planificare
- Planificare și luare a deciziilor – folosește cunoștințele și raționamentul pentru a selecta acțiuni optime: planificare pe termen scurt / lung, optimizare, selecția acțiunilor
- Acțiune / Execuție – componenta care execută deciziile: generare de text / conținut, control robotic, interacțiune cu API-uri, manipularea mediului
- Memorie – stochează experiențe, stări și rezultate anterioare: memorie pe termen scurt, memorie pe termen lung, buffer de experiență
- Interfață și comunicare – modul ce permite AI să interacționeze cu utilizatorii sau alte sisteme: NLP pentru dialog, API-uri, protocoale de comunicare
Platformele de inteligență artificială pot fi utilizate în cloud sau local, în propria infrastructură. AI on-premise oferă o combinație unică de securitate, performanță și control pe care mediile cloud-native nu o pot reproduce complet.
Alegerea implementării unei soluții de AI on-premise aduce numeroase beneficii:
- Controlul și securitatea datelor: întrucât toate procesările de date au loc în cadrul propriei infrastructuri, se reduce expunerea la atacuri externe și se obține o respectare mai ușoară a legilor privind rezidența datelor
- Optimizarea performanței: prin colocarea datelor și a resurselor de calcul se minimalizează latența și se optimizează performanța modelului
- Personalizare: se poate personaliza fiecare nivel al infrastructurii locale, de la rețeaua de date la containerele de modele – pentru a îndeplini cerințele specifice ale companiei. Acest nivel de control este greu de atins într-un mediu bazat pe cloud, cu mai mulți tenanți
- Previzibilitatea costurilor: deși costurile inițiale ale infrastructurii sunt ridicate, platformele locale pot duce la un cost total de proprietate mai mic în timp, prin eliminarea taxelor recurente bazate pe utilizare
- Integrare Legacy și Edge: sistemele locale se pot integra direct cu software-ul și hardware-ul existente în cadrul companiei, inclusiv senzori proprietari, echipamente industriale și alte tehnologii operaționale. Se pot importa date din aplicații existente fără expunere exterioară a companiei
- Orchestrare hardware și GPU: accesul direct la managementul infrastructurii permite gestionarea eficientă a resursele de calcul de înaltă performanță pentru antrenament și inferență
- Gestionarea flexibilă a ciclului de viață al modelului AI: există control asupra implementării, versionarea, revenirea la versiune și monitorizarea fără probleme a modelelor
- Controale avansate de acces: se poate implementa controlul accesului pe bază de roluri și accesul bazat pe politici pentru guvernanță și conformitate
- Observabilitate integrată: se obține vizibilitate asupra comportamentului modelului AI folosit, a jurnalelor de activități și a metricilor de infrastructură
- Suport pentru modele diverse: în mediul local se pot găzdui atât modele open-source, cât și modele closed-source cu aceeași ușurință
- Guvernanță și auditabilitate: toate activitățile sunt trasabile și conforme cu standardele interne și de reglementare
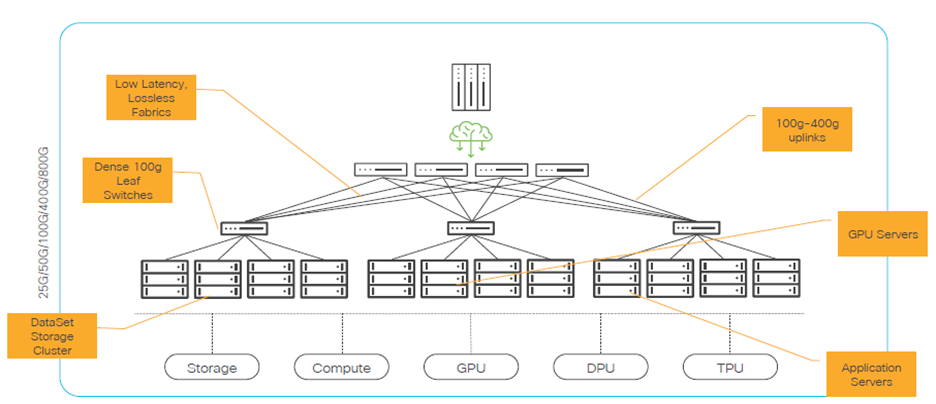
Arhitectura hardware și software a unei soluții AI on-premise
Construirea unei soluție de AI on-prem permite libertatea totală în alegerea hardware-ului și software-ului ce urmează a fi folosit, în funcție de nevoile fiecărei companii. Pe lângă componenta de IT, trebuie corect dimensionată și componentele de power și cooling. O infrastructură de AI complexă diferă față de o soluție clasică de IT prin consumul de power și indirect prin efortul de răcire. Dacă consumul tipic pentru un rack de echipamente cu echipare obișnuită de servere, storage și networking se ridică pe la 5-10 kW, în cazul unui rack cu servere GPU acest consum crește până la 30 kW și în unele implementări cu 4-6 servere GPU per rack poate atinge și depăși 60kW, în funcție de tipul GPU-urilor folosite.
Arhitectura hardware – pe straturi
Componenta de rețea – reprezintă coloana vertebrală pentru training / inference distribuit, oferind throughput mare și latență minimă. Este formată din:
- Switch-uri tip Leaf 100G/200G/400G/800G, care conectează direct nodurile GPU/compute/storage
- Switch-uri Spine/Core, cu uplinks de 100–800G între leaf și spine
Nodurile GPU (GPU Servers) – zona unde se întâmplă efectiv activitatea de training / inference.
Configurație tipică:
- 2–8 GPU‑uri per nod (NVIDIA B300/B200/H200/A100/L40, AMD MI300 etc.)
- 2× CPU (x86 sau ARM) cu 32–64 core-uri fiecare
- RAM: 512 GB – 2 TB
- 2–8× NIC 100G
- NVMe local pentru scratch / cache
Conectivitate GPU:
- pe nod: NVLink / NVSwitch
- între noduri: RoCEv2 / InfiniBand
Rol în ecosistem:
- training modele mari (LLM, vision, multimodal)
- inference la scară
- fine‑tuning, RAG, batch scoring
Nodurile de Compute / Application Servers – au ca rol managementul și controlul platformei. Acestea oferă:
- orchestrare (Kubernetes/OpenShift control plane, schedulere)
- microservicii de aplicație
- API gateways, front‑end, business logic
- feature engineering, data prep, pre/post‑processing
Ca hardware, nodurile de compute au CPU-uri rapide cu multe core-uri, plăci de rețea cu redundanță 25/50/100GbE, redundanță dual-port sau dual-NIC.
DPU / SmartNIC – preia din sarcinile CPU/GPU partea de rețea, securitate și storage dataplane:
Offload pentru:
- crypto/IPSec/TLS
- overlay networking (VXLAN/Geneve)
- storage (NVMe‑oF target/initiator)
- firewalling / microsegmentation
Ajută la izolare multi‑tenant și la reducerea jitter‑ului de latență în traficul de AI.
TPU / acceleratoare specializate – sunt procesoare specializate create de Google, optimizate pentru operații tensoriale folosite în machine learning, în special:
- matrici mari
- operații de tip multiply‑accumulate (MAC) (înmulțesc două valori și adună rezultatul la o sumă existentă)
- rețele neuronale dense și convoluționale
Storage Cluster – reprezintă sursa principală de stocare pentru datele de training, feature store, modele.
Tipuri de storage:
- scale‑out NAS (NFS, SMB Multichannel) pentru dataset‑uri mari
- obiect (S3 compatibil) pentru arhive și versionare de date/model
- NVMe‑oF / block pentru baze de date și metadata intensive
Caracteristici cheie:
- throughput secvențial foarte mare (citire streaming pentru GPU)
- multe IOPS random pentru metadata/ mici fișiere
- paralelism masiv (multi‑client, multi‑stream)
- snapshot / clone pentru experimente reproductibile
Arhitectura software
Primul nivel software al unui infrastructuri de AI este format din sistem de operare și virtualizare.
OS pe noduri, linux-based: RHEL, Ubuntu, SLES – cu:
- kernel tunat pentru RDMA, huge pages, NUMA
- drivere GPU (NVIDIA, AMD), DPU, InfiniBand/RoCE
Virtualizare / Containerizare: Kubernetes / OpenShift / Rancher / k8s vanilla.
Următorul nivel este cel de orchestrare și scheduling AI și reprezintă „creierul operațional” al unei platforme AI on‑prem. Este nivelul care decide unde, când și cum rulează joburile de AI (training, inferență, preprocesare, pipeline‑uri MLOps), astfel încât resursele scumpe: GPU, CPU, memorie, rețea să fie folosite eficient și predictibil.
Acest rol de orchestrare este jucat de obicei de Kubernetes / OpenShift, Kubeflow, etc. Acțiunile orchestrate:
- definește worker nodes GPU vs CPU
- lansarea joburilor de training/inferență
- gestionarea containerelor și serviciilor
- pornirea / oprirea pipeline‑urilor MLOps
- gestionarea dependențelor dintre etape
- monitorizarea stării nodurilor și a GPU‑urilor
- relansarea automată a joburilor eșuate
- pod priority, resource quotas, multi‑tenancy
Rolul de scheduling AI decide:
- pe ce nod GPU rulează un job
- câte GPU-uri primește
- cât CPU și RAM îi sunt alocate
- ce job are prioritate
- cum se împart resursele între utilizatori
- cum se evită supraîncărcarea unui nod
Arhitectura continuă cu nivelul AI/ML – framework‑uri și librării. Este nivelul în care se află:
- framework‑urile de machine learning (scikit‑learn, standardul pentru ML clasic; GBoost / LightGBM / CatBoost, folosite în scoring tabular, fraud detection, risk scoring
- librăriile pentru deep learning (PyTorch, standardul de facto pentru cercetare și producție; TensorFlow/Keras, folosit în enterprise și cloud)
- tool‑urile pentru procesarea datelor
- librăriile pentru accelerare hardware (GPU, DPU, TPU)
- runtime‑urile pentru inferență
- ecosistemul Python/conda
Nivelul de date și feature engineering acoperă tot ce se întâmplă între sursele de date și framework‑urile AI/ML. Include:
- colectarea datelor (datele sunt colectate, validate, normalizate, transformate și încărcate în data lake sau data warehouse)
- curățarea și validarea lor (în acest proces se realizează eliminarea valorilor lipsă, corectarea erorilor, deduplicare, validare statistică, detectarea anomaliilor, standardizarea formatelor)
- transformări (normalizare, standardizare, chunking, tokenizare, vectorizare)
- generarea de feature‑uri (feature engineering înseamnă transformarea datelor brute în feature‑uri relevante pentru modele)
- versionarea și guvernanța datelor
- pregătirea dataset‑urilor pentru training și inferență
Este un strat critic pentru performanță, acuratețe și reproductibilitate.
Stratul de MLOps și lifecycle management este „sistemul de operare” al întregii platforme AI. Dacă stratul AI/ML este motorul, MLOps este cutia de viteze, frânele, senzorii și tot ce ține mașina stabilă, sigură și repetabilă.
Este ansamblul de procese, tool‑uri și practici care asigură:
- dezvoltarea
- antrenarea
- versionarea
- testarea
- deployment‑ul
- monitorizarea
- guvernanța
- retragereaunui model AI pe tot parcursul vieții sale
Componenta de observabilitate, securitate și guvernanță este ceea ce transformă o platformă AI on‑prem într-o soluție enterprise robustă, auditată, controlată și sigură. Este nivelul care asigură că tot ce se întâmplă în platformă este vizibil, controlat, conform și protejat. Observabilitatea în AI înseamnă capacitatea de a vedea ce se întâmplă în platformă, în timp real și istoric, la nivel:
- hardware (GPU, CPU, memorie, rețea)
- software (containere, servicii, pipeline-uri)
- modele (latență, drift, acuratețe)
- date (fluxuri, erori, calitate)
Securitatea într-o platformă AI este mult mai complexă decât într-un sistem IT clasic, pentru că trebuie protejate:
- date sensibile
- modele
- pipeline-uri
- GPU-uri (resurse scumpe)
- accesul la inferență
- accesul la training
Guvernanța este partea care asigură că platforma AI este:
- conformă
- auditată
- controlată
- documentată
- predictibilă
- responsabilă
Dimensionarea unei soluții de AI
Implementarea cu succes a unei platforme AI on‑premise depinde în mod critic de dimensionarea corectă a resurselor, deoarece aceasta influențează direct:
- performanța modelelor
- scalabilitatea sistemului
- costurile operaționale și investiționale
- eficiența utilizării GPU‑urilor
- timpul de antrenare și inferență
- experiența utilizatorilor și predictibilitatea platformei
În AI, subdimensionarea duce la blocaje și GPU-uri idle, iar supradimensionarea duce la costuri inutile. Echilibrul este cheia. Elementele care ajută la dimensionare corectă a unei soluții de AI:
- Număr de parametrii: numărul total de valori ajustabile pe care modelul le învață în timpul antrenării (7B, 13B, 70B, 405B)
- Context window: număr de tokeni procesați simultan
- Tip model: text, imagine, cod, multimodal
- Mod de utilizare: training, fine-tuning, inferență
- Batch size: număr de exemple procesate simultan
- Precision: FP32, FP16, bfloat16, INT8
- SLA / latență: timp de răspuns cerut
- Concurență: număr de utilizatori simultani
Echipa noastră de specialiști, cu expertiză solidă în arhitecturi AI, infrastructură, networking și securitate, este pregătită să sprijine companiile în proiectarea și implementarea unor soluții AI on‑premise performante, scalabile și adaptate nevoilor lor. Pentru mai multe informații sau detalii comerciale, vă rugăm să ne contactați la: [email protected].